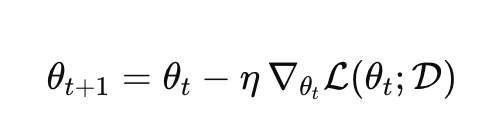
In-context learning (ICL) is the ability of foundation models to adapt their behavior at inference time by conditioning on examples, instructions, and other task-specific information placed directly in the prompt. This post builds a practical, cross-modal view of ICL: how it shows up in large language models, how it changes when images enter the context, and what it means for robotics, where “outputs” are actions rather than tokens. We will develop an intuition for what ICL is (and is not), connect it to transformer mechanisms such as induction heads and long-context effects, and then walk through concrete prompting patterns, failure modes, and evaluation strategies. The goal is to leave you with a mental model and a playbook you can use to design, test, and deploy ICL-based systems across language, computer vision, and robotics.
Who it’s for
Key takeaways
The problem: task adaptation is expensive
Traditional adaptation usually means:
That pipeline is slow, compute-heavy, and operationally risky. Even “lightweight” updates (LoRA/adapters) still require data management, evaluation cycles, and model versioning.
The promise: adapt at inference time using demonstrations
ICL offers a different workflow: you keep the model fixed and change only the prompt. As popularized by large-scale language models, models can often solve new tasks from a handful of labeled examples in the prompt without any gradient updates (e.g., GPT-3 style few-shot prompting).
Why multimodal + robotics makes it more interesting
Once you leave pure text, the challenges get sharper:
ICL becomes a unifying interface: the same idea (provide demonstrations in the prompt) can drive behavior across text outputs, visual reasoning outputs, and action outputs.
Definition: conditioning on context vs updating parameters
A clean way to say it:
Fine-tuning changes parameters:


ICL changes the input to the model, not theta:

So the “learning” is in how the model uses the prompt context to condition its outputs.
Few-shot, zero-shot, instruction following: how they relate
“Context as a temporary dataset” mental model
A useful mental model:
This framing helps you design prompts: choose examples that span edge cases, match deployment distribution, and reduce ambiguity.
A tiny running example (text + image + action)
We will reuse a single task across modalities: “Sort-and-route”.
Goal: Determine the correct bin for an item: `RECYCLE`, `COMPOST`, or `TRASH`.
We’ll keep the output schema fixed:
{"bin": "RECYCLE|COMPOST|TRASH", "confidence": 0.0} You do not need mechanistic interpretability to use ICL well, but a little intuition explains why formatting and example placement can make or break performance.
Transformer attention as retrieval over demonstrations
Transformers can attend to earlier tokens (and, in multimodal models, earlier visual tokens) that look relevant to the current query. This enables a kind of “retrieve-and-apply” behavior:
Mechanistic work has identified induction heads as one plausible circuit that supports pattern copying and continuation, which aligns with few-shot behavior in sequence models.
Pattern completion vs implicit task inference (“latent task” viewpoint)
Two helpful lenses:
Many theoretical and empirical analyses suggest that ICL is often closer to identifying the task than “learning new knowledge.”
Why ordering, formatting, and representativeness matter
ICL is fragile to:
A consistent template reduces the search space of “what task is being asked.”
Context length constraints + “lost-in-the-middle”
Even long-context models may not use all context uniformly. In long prompts, performance can drop when critical information is buried in the middle rather than near the beginning or end. This matters for demonstration-heavy prompts:
Classic capabilities-In language tasks, ICL can support:
A landmark example is the observation that sufficiently large language models can perform many tasks in a few-shot setting without gradient updates.
Tool-use / function calling as structured ICL
Tool-use can be seen as ICL with a strict output contract:
This often outperforms “free-form” prompting because the model’s job is narrowed: produce valid structured output.
Prompt “programs”: chain-of-thought vs structured reasoning (safe + practical)
You can ask models to “reason,” but for production systems prefer:
A safe pattern is to request a brief explanation and keep the main decision machine-checkable.
Mini demo: few-shot schema extraction
Task: Extract a normalized record from a short message.
Prompt template
You are a data extraction system.
Return ONLY valid JSON matching this schema:
{"name": string, "email": string|null, "company": string|null, "bin": "RECYCLE"|"COMPOST"|"TRASH", "confidence": number}
Examples:
Input: "Hi, I'm Ana from GreenLoop. This is a glass bottle. ana@greenloop.io"
Output: {"name":"Ana","email":"ana@greenloop.io","company":"GreenLoop","bin":"RECYCLE","confidence":0.92}
Input: "Compostable paper cup, I'm Ben at CafeKraft"
Output: {"name":"Ben","email":null,"company":"CafeKraft","bin":"COMPOST","confidence":0.70}
Input: "Plastic wrapper. Contact: li@noodlebar.de"
Output: {"name":null,"email":"li@noodlebar.de","company":"Noodlebar","bin":"TRASH","confidence":0.66}
Now extract:
Input: "I’m Sara at UniSiegen. Banana peel. sara@uni-siegen.de"
Output:
Evaluation ideas
Multimodal ICL often means: **the context contains images and text** interleaved as demonstrations, and the query includes a new image.
5.1 Vision-language ICL
Common VLM tasks:
Some VLM architectures are designed to ingest interleaved image-text sequences and perform few-shot prompting with examples.
Example (conceptual)
[Image A]
Q: Which bin? A: {"bin":"RECYCLE","confidence":0.90}
[Image B]
Q: Which bin? A: {"bin":"TRASH","confidence":0.80}
[Image C]
Q: Which bin? A: ?
Tip: Keep the exact output format identical across examples.
5.2 In-context visual classification
This is the “support set” idea: provide exemplar images with labels, then classify a new image.
How this differs from training a linear probe:
In practice, this can be more flexible for fast iteration, but less stable than learned adapters.
5.3 In-context dense/structured prediction (harder)
Dense tasks like detection/segmentation require structured outputs:
Some VLMs can approximate these via text-based formats (e.g., “box=(x1,y1,x2,y2)”), but results are often limited:
When you need reliability, tools help:
Mini demo idea A: few-shot product categorization (4 labeled image examples)
Output schema
{"category": "BOTTLE|CAN|PAPER|FOOD_WASTE|PLASTIC_WRAP|OTHER", "bin":"RECYCLE|COMPOST|TRASH", "confidence": 0.0} Prompt skeleton
You are a visual classification system.
Given an image of an item, output ONLY JSON in this schema:
{...}
Examples:
[Image 1: aluminum can]
Output: {"category":"CAN","bin":"RECYCLE","confidence":0.93}
[Image 2: banana peel]
Output: {"category":"FOOD_WASTE","bin":"COMPOST","confidence":0.91}
[Image 3: plastic wrapper]
Output: {"category":"PLASTIC_WRAP","bin":"TRASH","confidence":0.84}
[Image 4: glass bottle]
Output: {"category":"BOTTLE","bin":"RECYCLE","confidence":0.90}
Now classify:
[Image 5: query]
Output:
Evaluation
Mini demo idea B: visual analogies / ARC-style grid reasoning
ARC-style tasks can be framed as ICL with small input-output grids as demonstrations.
This is a good “pure reasoning” test for multimodal ICL because:
Robotics adds two twists:
6.1 Language-conditioned policies
Here, the prompt can include:
What counts as “context” in robotics

Example (text demonstration)
Task: place item into correct bin
Demo 1:
Item: "banana peel"
Plan: ["approach item","grasp","move to COMPOST bin","release"]
Demo 2:
Item: "glass bottle"
Plan: ["approach item","grasp","move to RECYCLE bin","release"]
Query:
Item: "plastic wrapper"
Plan:
6.2 Vision-language-action (VLA) models
VLA models unify:
The appeal:
6.3 Robot agents with tools
A practical systems view:
ICL shows up as:
Mini demo ideas
A) Few-shot pick-and-place variants
B) Failure recovery via one corrective demonstration
Safety note: why constraints/checks matter more in robotics than text
In robotics, you should assume the model may be wrong. Mitigations:
Treat ICL as a powerful interface, not a guarantee.
7) When ICL fails (and how to make it work)
Common failure modes
Retrieval strategies (RAG for demonstrations)
Instead of writing prompts by hand, build a demonstration library and retrieve:
Retrieve 3–8 high-quality demonstrations rather than 30 mediocre ones.
Robust prompting checklist
8) Measuring ICL: how to evaluate properly
Language metrics
Vision metrics
Robotics metrics
Practical evaluation harness
Run controlled ablations:
Pseudo-protocol
for seed in seeds:
demos = retrieve(k, seed)
for order in permutations(demos):
prompt = build_prompt(order, query)
y = model(prompt)
score(y)
report mean, std, and worst-case
9) Practical playbook: building an ICL system end-to-end
Step 1: define the task + output contract
Step 2: curate a demonstration library (gold examples)
2. Maintain versioning and audit trail.
Step 3: retrieve demos (embedding + metadata filters)
Step 4: inference orchestration (tooling, verifiers, fallback)
Step 5: monitoring + continuous improvement
“ICL vs fine-tuning vs adapters” decision table

10) Future directions (what’s next)
11) Conclusion
ICL is best viewed as context-driven task adaptation: the prompt becomes a temporary dataset and interface that steers a frozen model. In text, this enables rapid few-shot generalization; in vision-language, it enables interleaved demonstration prompting but can be less robust; and in robotics, it becomes a pathway from language and perception to actions, where safety and verification are non-negotiable.
Cheat sheet
Appendix
A) Prompt templates (language, vision-language, robotics)
A.1 Language: few-shot classification with JSON schema
System: You are a classification system. Output ONLY valid JSON.
Schema:
{"bin":"RECYCLE|COMPOST|TRASH","confidence":0.0}
Examples:
Input: "glass bottle"
Output: {"bin":"RECYCLE","confidence":0.92}
Input: "banana peel"
Output: {"bin":"COMPOST","confidence":0.90}
Input: "plastic wrapper"
Output: {"bin":"TRASH","confidence":0.85}
Query:
Input: "{USER_TEXT}"
Output:
A.2 Vision-language: interleaved image demonstrations
System: You are a visual classifier. Output ONLY valid JSON.
Schema:
{"bin":"RECYCLE|COMPOST|TRASH","confidence":0.0}
Examples:
[Image 1]
Output: {"bin":"RECYCLE","confidence":0.92}
[Image 2]
Output: {"bin":"COMPOST","confidence":0.90}
[Image 3]
Output: {"bin":"TRASH","confidence":0.85}
Query:
[Image Q]
Output:
A.3 Robotics: plan + tool calls (safer than raw actions)
System: You are a robot planner. Use tools; do not output raw motor commands.
Tools (JSON):
- perceive_item() -> {"item":"...", "bbox":[...], "confidence":...}
- plan_motion(target) -> {"trajectory_id":"..."}
- execute(trajectory_id) -> {"status":"ok|fail"}
- open_gripper(), close_gripper()
Return a JSON plan:
{"steps":[{"tool":"...", "args":{...}}], "safety_checks":[...], "confidence":0.0}
Demos:
Demo 1: ...
Demo 2: ...
Query: sort the item on the table into the correct bin.
Output:
B) Example formatting conventions (few-shot tables)
Use a single canonical format. For example:
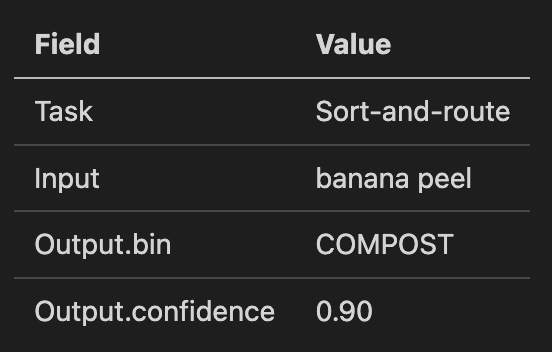
Repeat exactly for each demonstration, then the query row.
C) Glossary
D) References (grouped)
D.1 ICL foundations and analysis
D.2 Multimodal in-context learning (vision-language)
D.3 Robotics and VLA models